2025. 7. 3. 23:14ㆍ카테고리 없음
문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 이 문제에서는 우선순위 디스크 컨트롤러라는 가상의 장치를 이용한다고 가정합니다. 우선순위 디스크 컨트롤러는 다음과 같이 동작합니다.
- 어떤 작업 요청이 들어왔을 때 작업의 번호, 작업의 요청 시각, 작업의 소요 시간을 저장해 두는 대기 큐가 있습니다. 처음에 이 큐는 비어있습니다.
- 디스크 컨트롤러는 하드디스크가 작업을 하고 있지 않고 대기 큐가 비어있지 않다면 가장 우선순위가 높은 작업을 대기 큐에서 꺼내서 하드디스크에 그 작업을 시킵니다. 이때, 작업의 소요시간이 짧은 것, 작업의 요청 시각이 빠른 것, 작업의 번호가 작은 것 순으로 우선순위가 높습니다.
- 하드디스크는 작업을 한 번 시작하면 작업을 마칠 때까지 그 작업만 수행합니다.
- 하드디스크가 어떤 작업을 마치는 시점과 다른 작업 요청이 들어오는 시점이 겹친다면 하드디스크가 작업을 마치자마자 디스크 컨트롤러는 요청이 들어온 작업을 대기 큐에 저장한 뒤 우선순위가 높은 작업을 대기 큐에서 꺼내서 하드디스크에 그 작업을 시킵니다. 또, 하드디스크가 어떤 작업을 마치는 시점에 다른 작업이 들어오지 않더라도 그 작업을 마치자마자 또 다른 작업을 시작할 수 있습니다. 이 과정에서 걸리는 시간은 없다고 가정합니다.
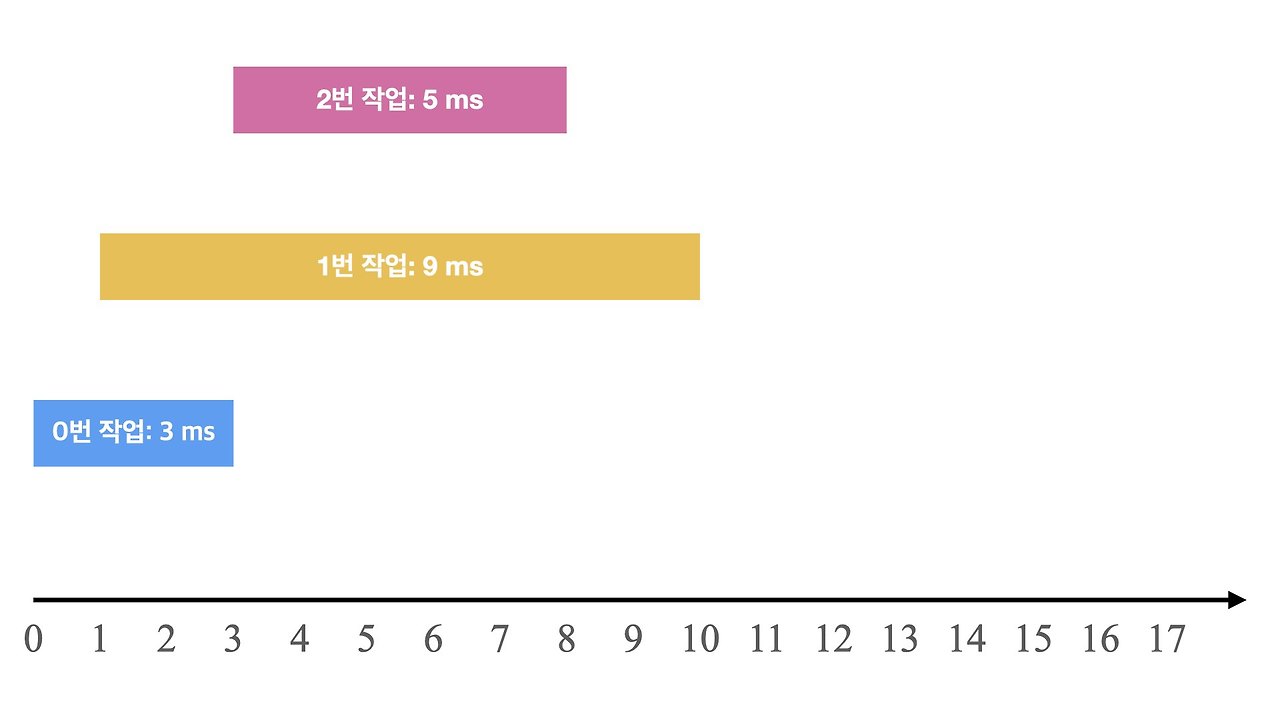
예를 들어
- 0ms 시점에 3ms가 소요되는 0번 작업 요청
- 1ms 시점에 9ms가 소요되는 1번 작업 요청
- 3ms 시점에 5ms가 소요되는 2번 작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 다음과 같습니다.
이 요청을 우선순위 디스크 컨트롤러가 처리하는 과정은 다음 표와 같습니다.
시점하드디스크대기 큐디스크 컨트롤러| 0ms | [] | ||
| 0ms | [[0번, 0ms, 3ms]] | 0번 작업 요청을 대기 큐에 저장 | |
| 0ms | 0번 작업 시작 | [] | 대기 큐에서 우선순위가 높은 0번 작업을 꺼내서 작업을 시킴 |
| 1ms | 0번 작업 중 | [[1번, 1ms, 9ms]] | 1번 작업 요청을 대기 큐에 저장 |
| 3ms | 0번 작업 완료 | [[1번, 1ms, 9ms]] | |
| 3ms | [[1번, 1ms, 9ms], [2번, 3ms, 5ms]] | 2번 작업 요청을 대기 큐에 저장 | |
| 3ms | 2번 작업 시작 | [[1번, 1ms, 9ms]] | 대기 큐에서 우선순위가 높은 2번 작업을 꺼내서 작업을 시킴 |
| 8ms | 2번 작업 완료 | [[1번, 1ms, 9ms]] | |
| 8ms | 1번 작업 시작 | [] | 대기 큐에서 우선순위가 높은 1번 작업을 꺼내서 작업을 시킴 |
| 17ms | 1번 작업 완료 | [] |
모든 요청 작업을 마쳤을 때 각 작업에 대한 반환 시간(turnaround time)은 작업 요청부터 종료까지 걸린 시간으로 정의합니다. 위의 우선순위 디스크 컨트롤러가 처리한 각 작업의 반환 시간은 다음 그림, 표와 같습니다.

| 0번 | 0ms | 3ms | 3ms(= 3ms - 0ms) |
| 1번 | 1ms | 17ms | 16ms(= 17ms - 1ms) |
| 2번 | 3ms | 8ms | 5ms(= 8ms - 3ms) |
우선순위 디스크 컨트롤러에서 모든 요청 작업의 반환 시간의 평균은 8ms(= (3ms + 16ms + 5ms) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 정수 배열 jobs가 매개변수로 주어질 때, 우선순위 디스크 컨트롤러가 이 작업을 처리했을 때 모든 요청 작업의 반환 시간의 평균의 정수부분을 return 하는 solution 함수를 작성해 주세요.
제한 사항
- 1 ≤ jobs의 길이 ≤ 500
- jobs[i]는 i번 작업에 대한 정보이고 [s, l] 형태입니다.
- s는 작업이 요청되는 시점이며 0 ≤ s ≤ 1,000입니다.
- l은 작업의 소요시간이며 1 ≤ l ≤ 1,000입니다.
입출력 예jobsreturn
| [[0, 3], [1, 9], [3, 5]] | 8 |
입출력 예 설명
입출력 예 #1
- 문제에 주어진 예와 같습니다.
- 문제 분석
각 작업은 [요청 시점, 소요 시간] 형태로 주어짐
하드디스크는 한번에 하나의 작업만 수행 가능
대기 큐에는 요청된 작업만 들어 있음
작업 우선순위 결정
1. 소요시간 짧은 작업 우선
2. 요청 시점이 빠른 작업
3. 작업 번호가 작은 순
목표: 모든 작업의 평균 반환시간의 정수 부분
반환시간 = 하나의 작업이 요청된 시점에서부터 완료된 시점까지 걸린 시간
반환 시간 = 작업 종료 시각 - 작업 요청 시각
현재 시간에 처리할 수 있는 작업이 어떤 것들이 있는지 알기 쉬우려면 작업이 요청되는 시점을 기준으로 정렬해야함
- 구현
현재 시간에 가능한 작업들을 우선순위 큐에 넣고 소요시간이 가장 적인 작업을 우선순위 큐에서 꺼냄
그 이후 현재 시간에 꺼낸 작업의 소요시간을 더해 현재 시간 갱신하고, 우선순위 큐에 현재 시간에 가능한 작업을 다시넣고 이 과정을 반복
최종 코드
import java.util.*;
class Solution {
public int solution(int[][] jobs) {
// 작업 요청되는 시점이 빠른 순서로 정렬
Arrays.sort(jobs, (j1, j2) -> j1[0] - j2[0]);
Queue<int[]> pq = new PriorityQueue<>((j1, j2) -> j1[1] - j2[1]);
int currentTime = 0;
int completedJobs = 0;
int totalResponseTime = 0;
int jobIndex = 0;
// 현재 시간에 처리할 수 있는 작업들 중에서 작업의 소요시간이 가장 적은 작업부터 처리
while (completedJobs < jobs.length) {
// 현재 시간에서 처리할수있는 작업을들 우선순위 큐에 삽입
while(jobIndex < jobs.length && jobs[jobIndex][0] <= currentTime) {
pq.add(jobs[jobIndex]);
jobIndex++;
}
// 우선순위 큐 이용해서 소요시간이 가장 적은 작업 선택
// 작업의 요청부터 종료까지 걸린시간 더해주기
// 현재시간 업데이트
if(!pq.isEmpty()) {
int[] job = pq.remove();
currentTime = currentTime + job[1];
totalResponseTime = totalResponseTime + currentTime - job[0];
completedJobs++;
} else {
currentTime = jobs[jobIndex][0];
}
}
return totalResponseTime / jobs.length;
}
}